Accepted by IEEE RA-L / IROS 2022 Full Paper
Abstract. While quadruped robots usually have good stability and load capacity, bipedal robots offer a higher level of flexibility / adaptability to different tasks and environments. A multi-modal legged robot can take the best of both worlds. In this paper, we show a complete pipeline of design, control, and sim-to-real transfer of a multi-modal legged robot. We 1) design an additional supporting structure for a quadruped robot, 2) evaluate a class of novel hybrid learning-based algorithms combining different reinforcement learning algorithms (Twin Delayed Deep Deterministic Policy Gradients and Soft Actor Critic) and black-box parameter optimisers (Evolutionary Strategy and Bayesian Optimisation), and 3) propose a sim-to-real transfer technique. We use parameter optimisers to tune a conventional feedback controller simultaneously with the training of an RL agent that solves the residual task. Experimental results show that our proposed algorithms have the best performance in simulation and competitive performance on the real robot with our sim-to-real technique. Overall, our multi-modal robot could successfully switch between biped and quadruped, and walk in both modes.
Multimodal Transition Scheme
The multi-modal transition strategy described in Sec. II in the paper and a reverse action sequence can both perform well on the real robot, as shown in the figures below (Fig. 4 in the paper) and the supplementary video. In the quadruped mode, the additional supporting structure does not affect the quadruped locomotion controller; in the bipedal mode, the supporting structure can successfully provide a supporting polygon for the robot to keep balance. In this way, the robot can arbitrarily switch between these two locomotion modes.




Bipedal Locomotion Control
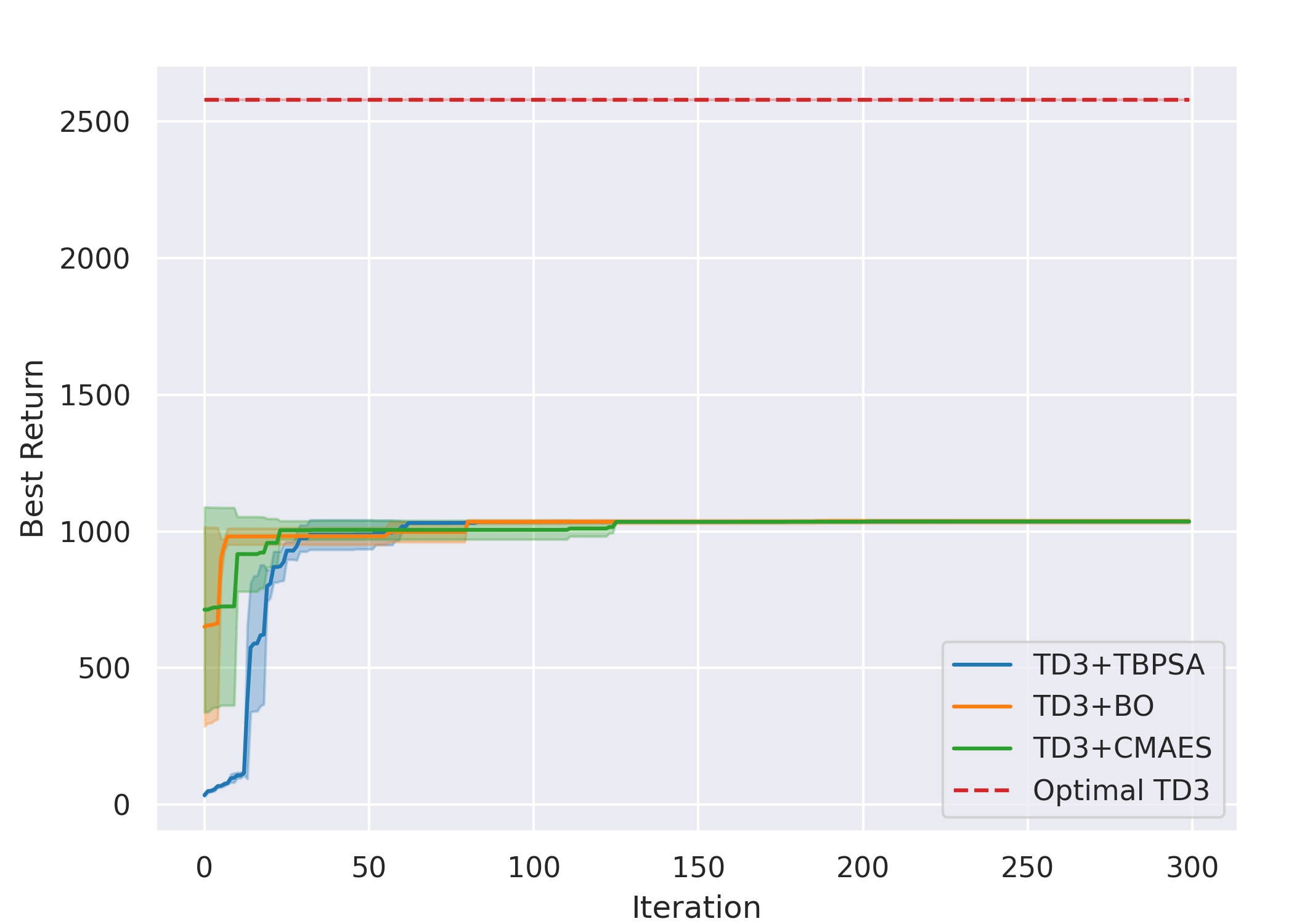
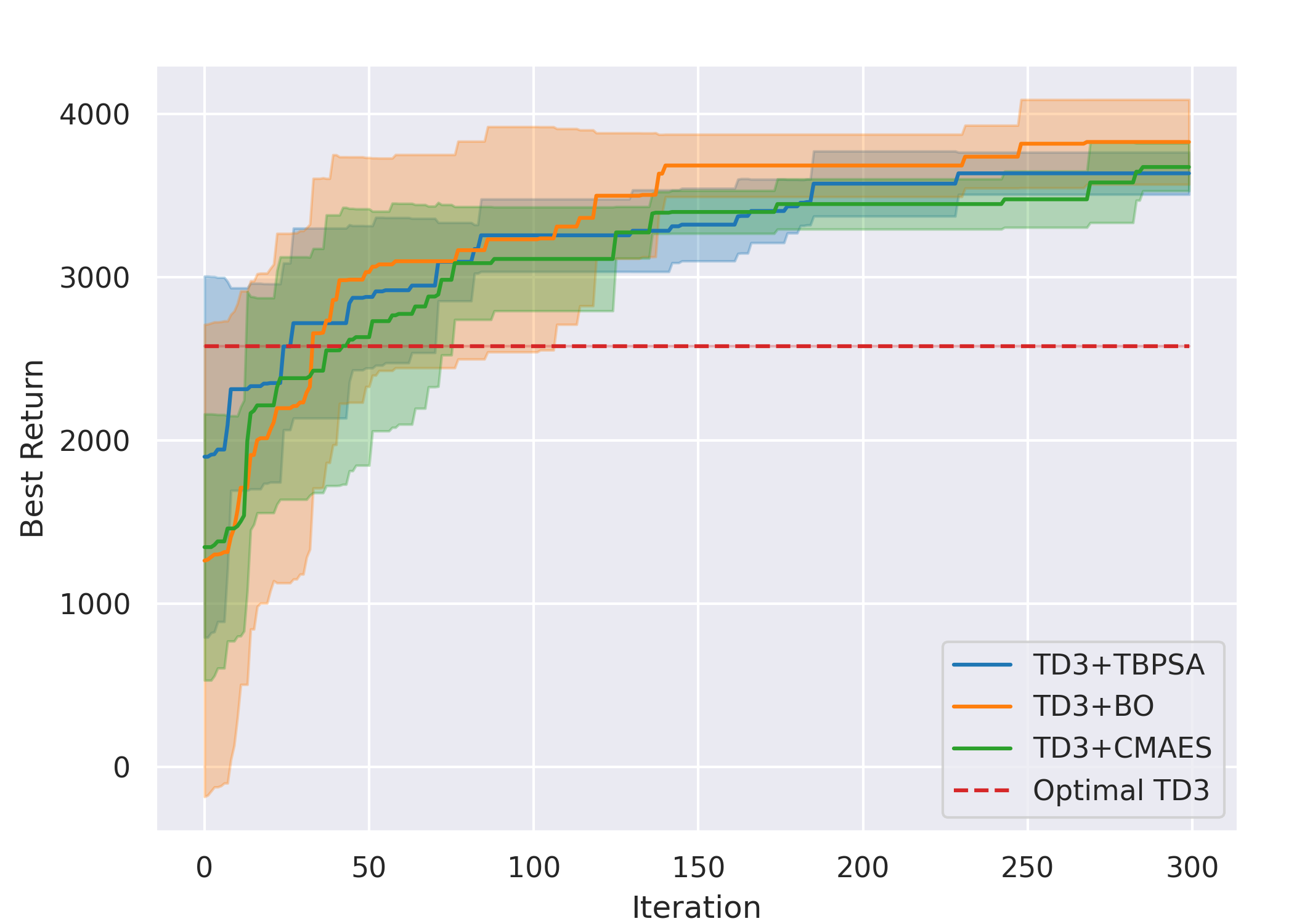
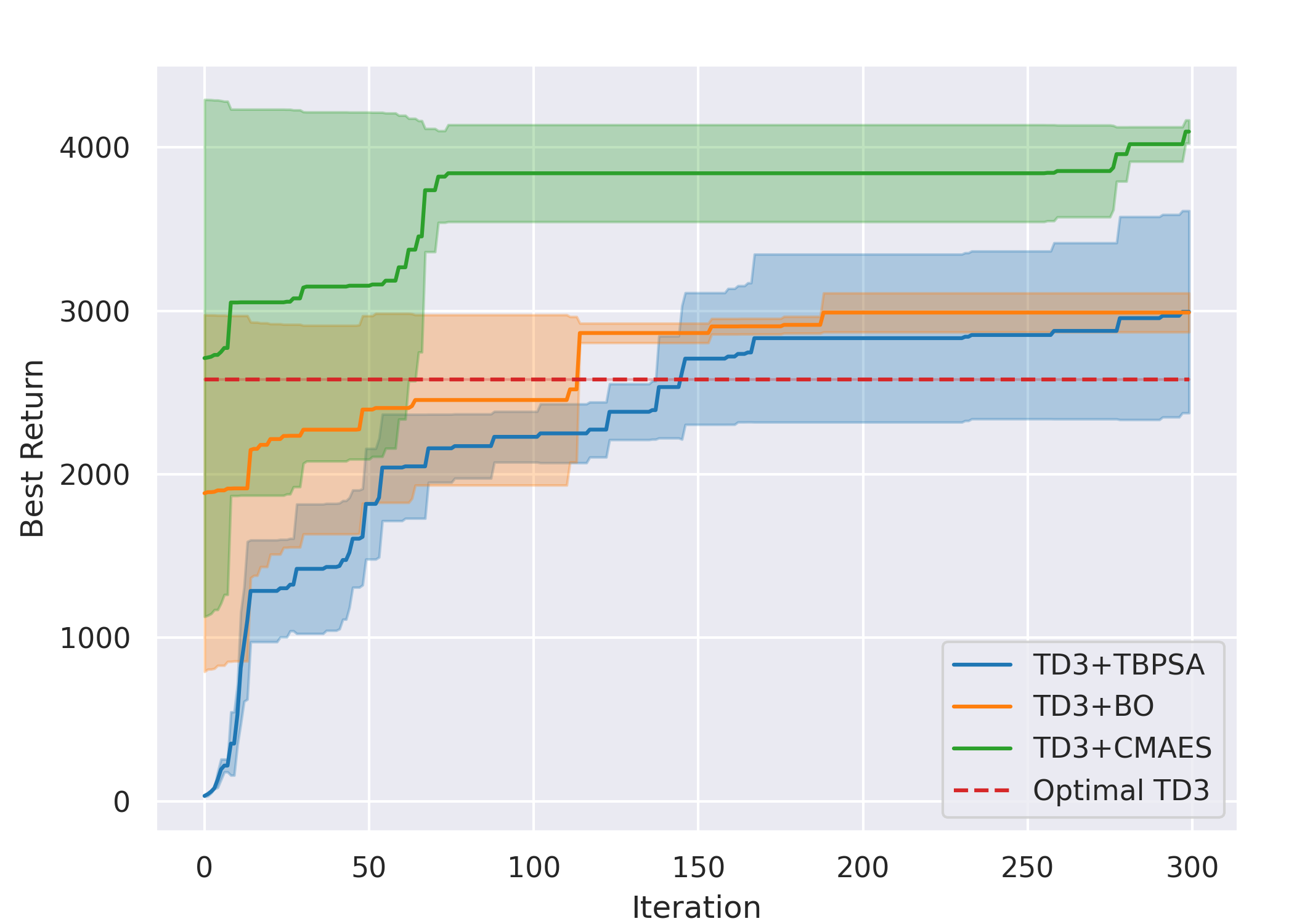
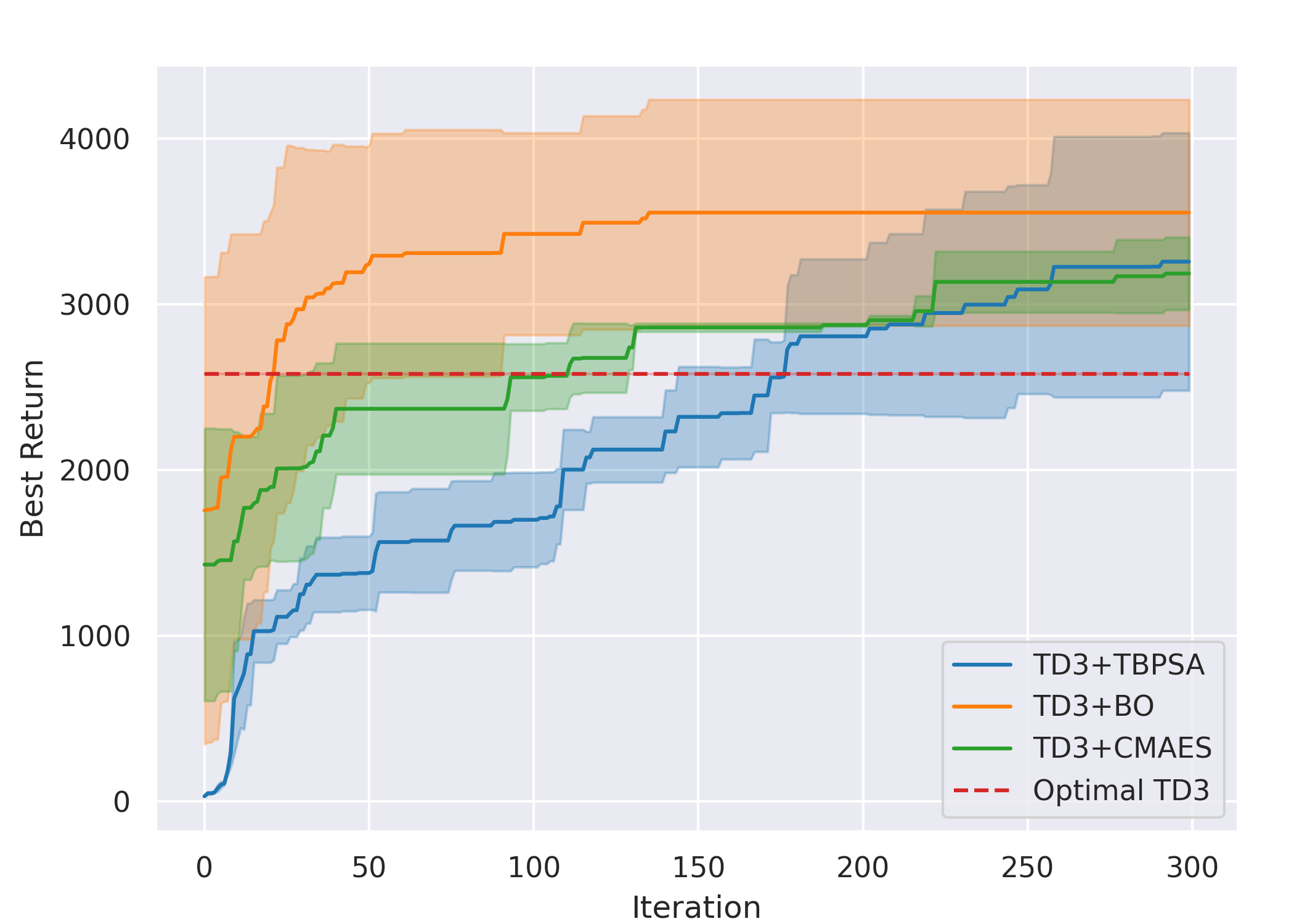
Overall, for all cases except methods involving TD3 with the Line gait, all six ARRL combinations have a better performance than their corresponding underlying pure RL. For motion primitives of Sine, Rose, and Triangle, ARRL combinations involving TD3 generally have a better performance than combinations involving SAC and pure block-box optimisers.
ARRL with SAC
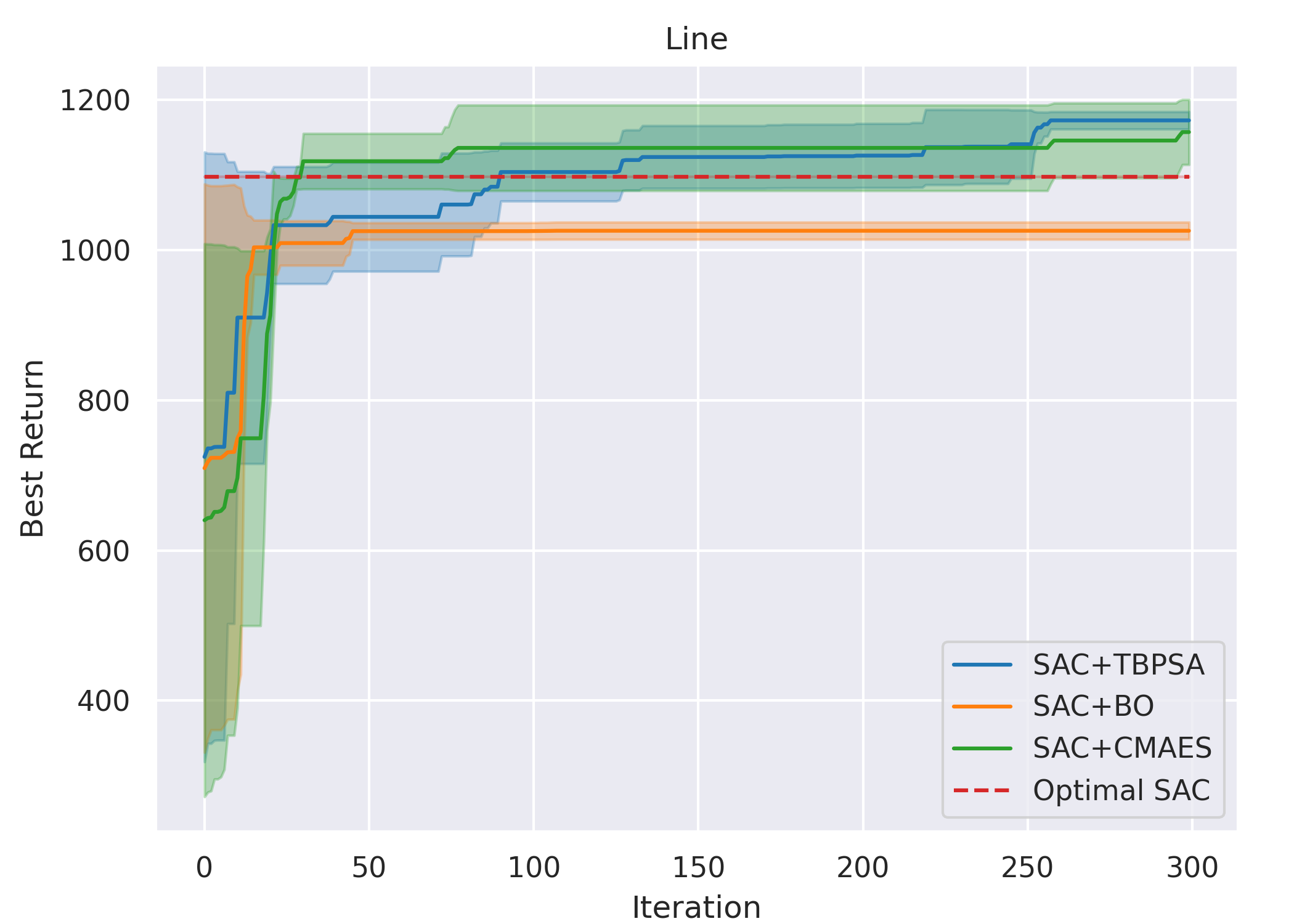
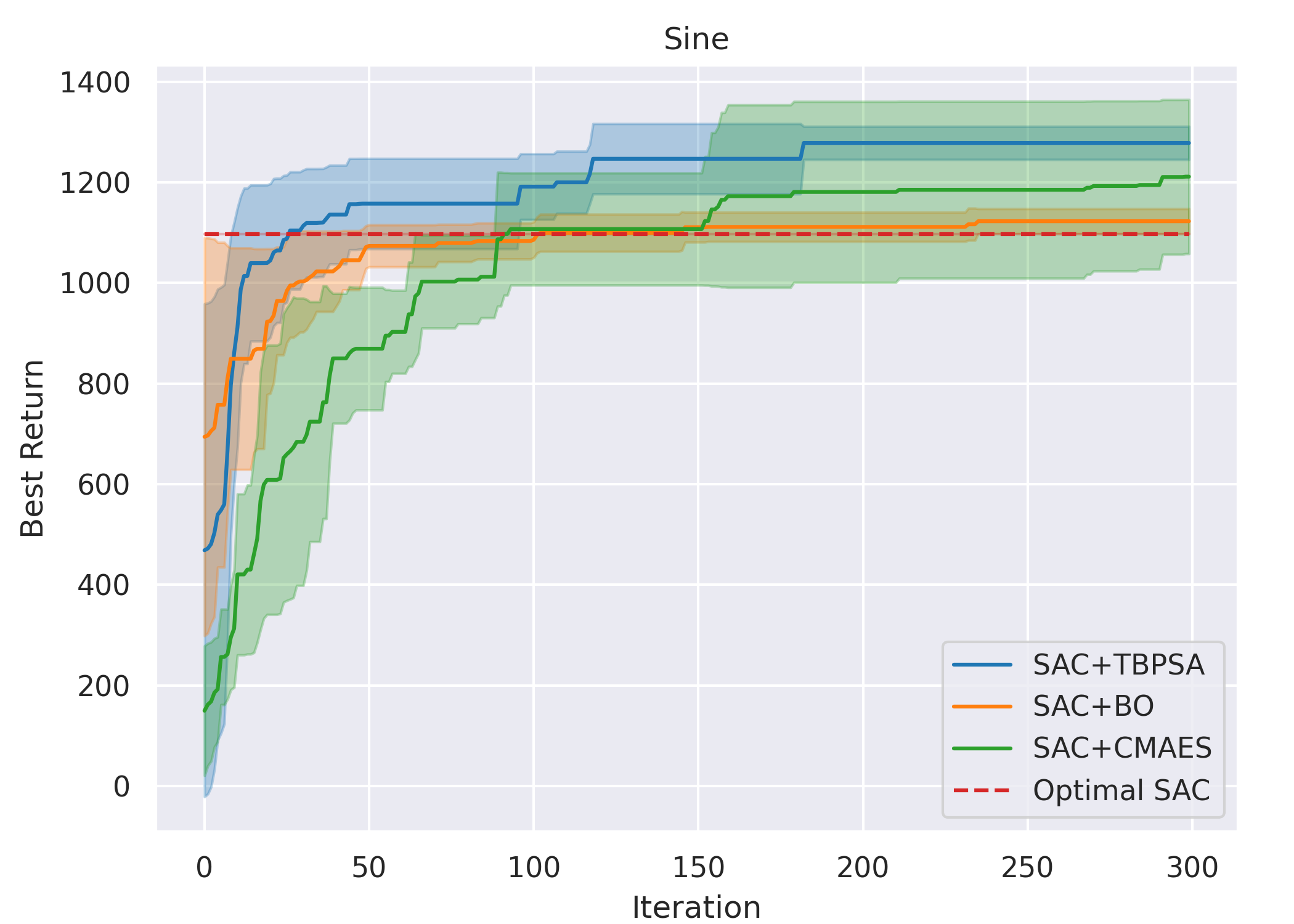
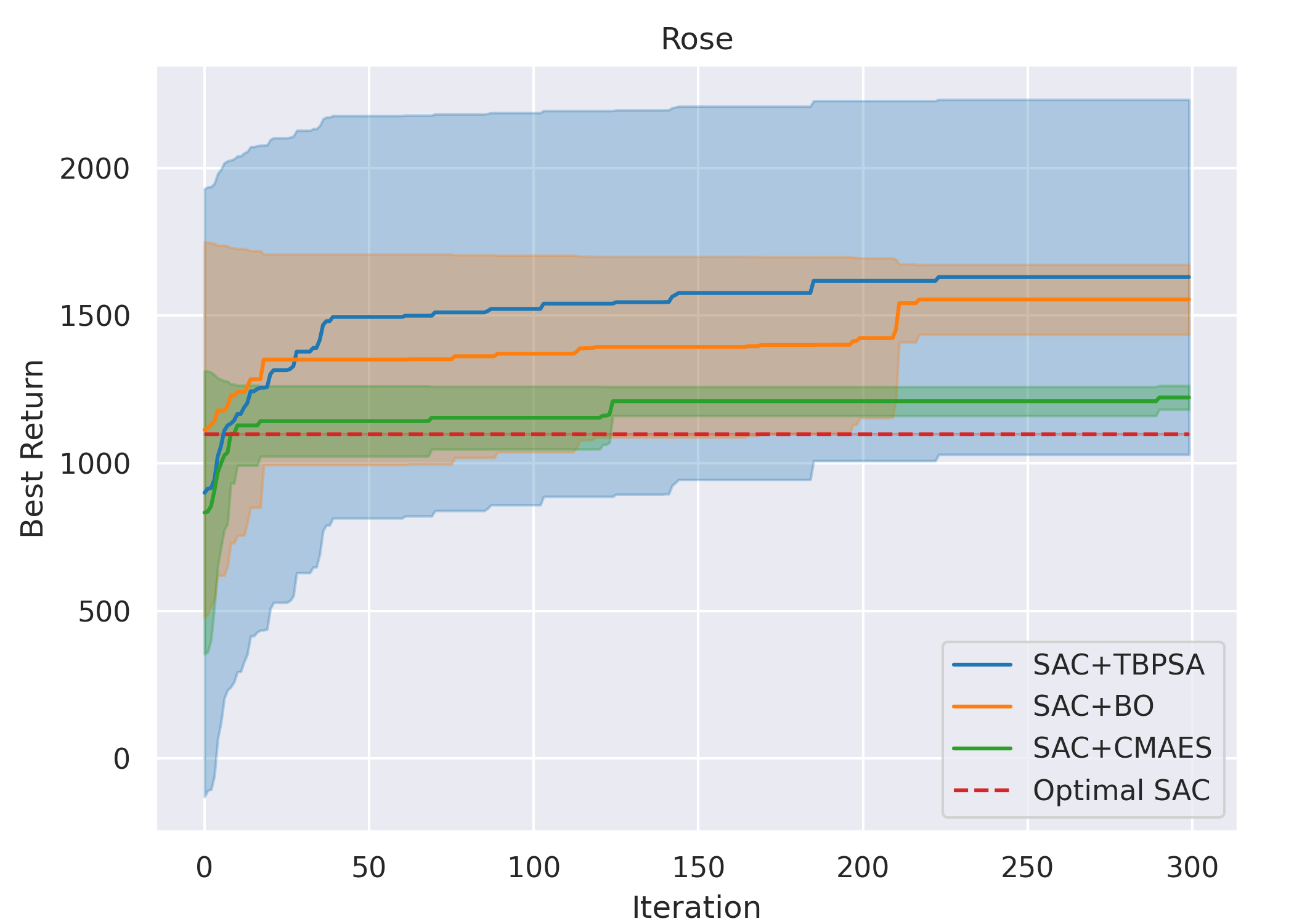
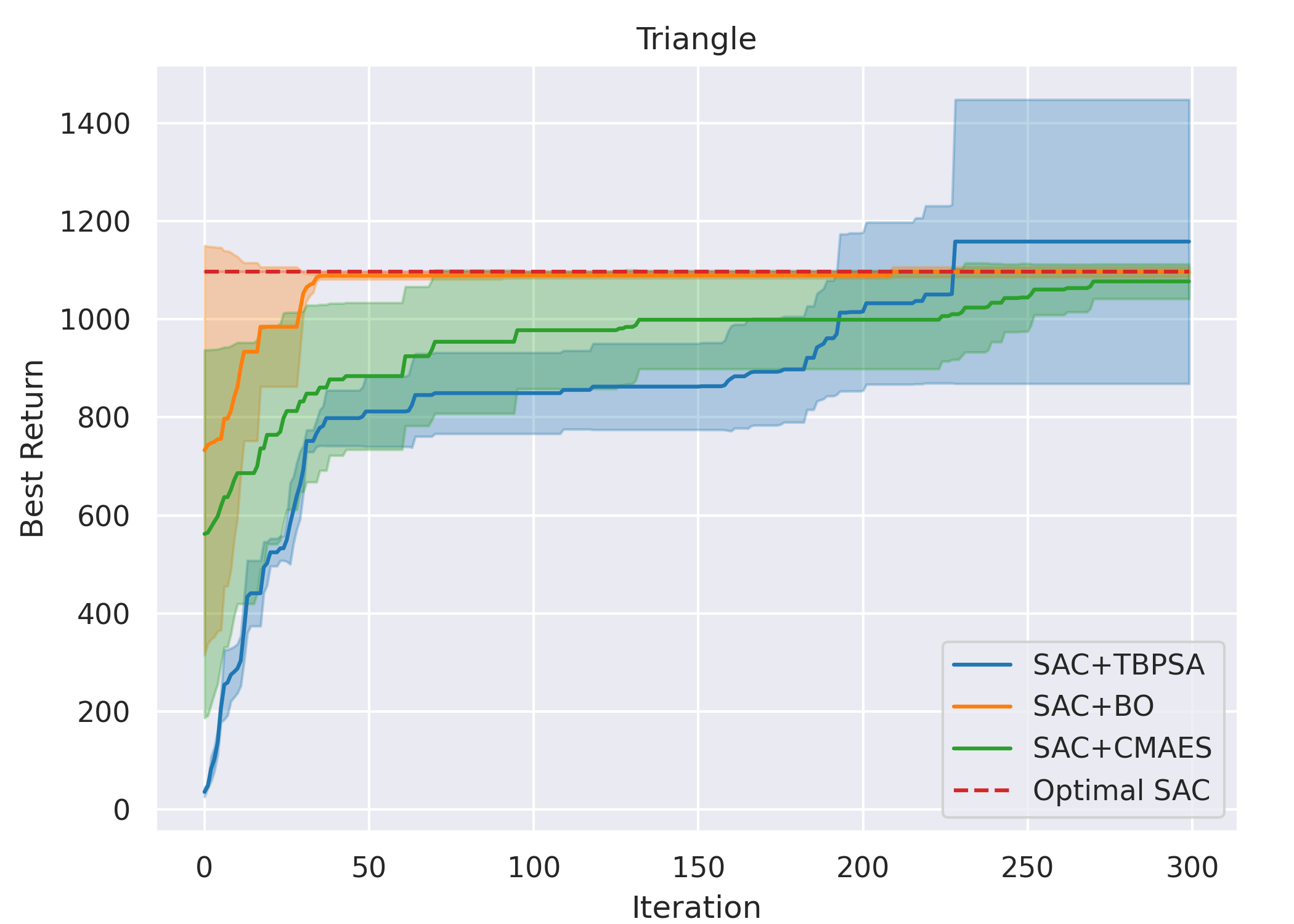
ARRL with TD3
Code
Code is available on Github. Includes:
• Simulation environments (with PyBullet).
• Training/testing code (with TensorFlow/Python).
• Program on the real robot (with TensorFlow/C++).
• STL files for the supporting structures.
Bibtex
title={Multi-Modal Legged Locomotion Framework with Automated Residual Reinforcement Learning},
author={Yu, Chen and Rosendo, Andre},
journal={IEEE Robotics and Automation Letters},
year={2022},
volume={7},
number={4},
pages={10312-10319},
doi={10.1109/LRA.2022.3191071}
}
Acknowledgements
Special thanks to Jinyue Cao, Heng Zhang, Zhongwei Luo for mathematical advice; Xiaozhu Lin, Wenqing Jiang for hardware support; Zhikang Liu, Jun Gu for video shooting.